 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Analysis of Variational Quantum Eigensolver
May 27, 2026The Variational Quantum Eigensolver (VQE) is a fundamental algorithm in quantum computing, yet a coherent geometric characterization of VQE remains missing due to fragmented analyses across fixed-ansatz and adaptive-circuit formulations. In this paper, we establish a geometric analysis of VQE in terms of optimization landscape, initialization guarantee, and noise robustness. First, we study the optimization landscape via an ansatz-free product-unitary formulation over the unitary group, unifying both paradigms. For the single-unitary case, we establish linear convergence of Riemannian gradient descent (RGD) and prove the strict saddle property. For the product-unitary case, we show the convergence rate deteriorates polynomially with circuit depth, providing a geometric explanation of the barren plateau phenomenon. Second, we prove that small-angle random Pauli-rotation circuits satisfy the required initialization conditions with high probability. Third, we show that RGD retains linear convergence under finite-shot measurements, and that coefficient-adaptive allocation achieves strictly lower statistical error than uniform sampling under a fixed measurement budget.
Statistical and Algorithmic Foundations of Probing Quantum Systems with Compressive Measurements: A Review
May 26, 2026Quantum state tomography (QST) is a fundamental task in quantum information science that aims to reconstruct unknown quantum states from measurement data. However, the exponential growth of Hilbert-space dimension with system size makes full tomography of general quantum states statistically and computationally prohibitive. This challenge has motivated extensive research on structured quantum state tomography, where prior structure, such as low-rankness, tensor-network representations, shallow quantum circuits, and neural quantum states, can substantially reduce the effective degrees of freedom and enable scalable recovery. In this review, we provide a unified perspective on QST for structured quantum states through three closely related themes: compact state representations, measurement design, and computational algorithms. After reviewing common models for structured quantum states, we survey existing work on geometric preservation properties of measurement frameworks, ranging from informationally complete POVMs to randomized measurements, and their implications for sample complexity. On the algorithmic side, we review optimization methods for reconstructing structured quantum states from empirical measurements. By connecting QST with broader principles from compressive sensing, matrix sensing, and structured inverse problems, this survey highlights common theoretical foundations underlying sample complexity, measurement efficiency, and scalable recovery.
Learning to Adapt: In-Context Learning Beyond Stationarity
Apr 13, 2026Transformer models have become foundational across a wide range of scientific and engineering domains due to their strong empirical performance. A key capability underlying their success is in-context learning (ICL): when presented with a short prompt from an unseen task, transformers can perform per-token and next-token predictions without any parameter updates. Recent theoretical efforts have begun to uncover the mechanisms behind this phenomenon, particularly in supervised regression settings. However, these analyses predominantly assume stationary task distributions, which overlook a broad class of real-world scenarios where the target function varies over time. In this work, we bridge this gap by providing a theoretical analysis of ICL under non-stationary regression problems. We study how the gated linear attention (GLA) mechanism adapts to evolving input-output relationships and rigorously characterize its advantages over standard linear attention in this dynamic setting. To model non-stationarity, we adopt a first-order autoregressive process and show that GLA achieves lower training and testing errors by adaptively modulating the influence of past inputs -- effectively implementing a learnable recency bias. Our theoretical findings are further supported by empirical results, which validate the benefits of gating mechanisms in non-stationary ICL tasks.
FlashSampling: Fast and Memory-Efficient Exact Sampling
Mar 16, 2026Sampling from a categorical distribution is mathematically simple, but in large-vocabulary decoding, it often triggers extra memory traffic and extra kernels after the LM head. We present FlashSampling, an exact sampling primitive that fuses sampling into the LM-head matmul and never materializes the logits tensor in HBM. The method is simple: compute logits tile-by-tile on chip, add Gumbel noise, keep only one maximizer per row and per vocabulary tile, and finish with a small reduction over tiles. The fused tiled kernel is exact because $\argmax$ decomposes over a partition; grouped variants for online and tensor-parallel settings are exact by hierarchical factorization of the categorical distribution. Across H100, H200, B200, and B300 GPUs, FlashSampling speeds up kernel-level decode workloads, and in end-to-end vLLM experiments, it reduces time per output token by up to $19%$ on the models we test. These results show that exact sampling, with no approximation, can be integrated into the matmul itself, turning a bandwidth-bound postprocessing step into a lightweight epilogue. Project Page: https://github.com/FlashSampling/FlashSampling.
RuCL: Stratified Rubric-Based Curriculum Learning for Multimodal Large Language Model Reasoning
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a prevailing paradigm for enhancing reasoning in Multimodal Large Language Models (MLLMs). However, relying solely on outcome supervision risks reward hacking, where models learn spurious reasoning patterns to satisfy final answer checks. While recent rubric-based approaches offer fine-grained supervision signals, they suffer from high computational costs of instance-level generation and inefficient training dynamics caused by treating all rubrics as equally learnable. In this paper, we propose Stratified Rubric-based Curriculum Learning (RuCL), a novel framework that reformulates curriculum learning by shifting the focus from data selection to reward design. RuCL generates generalized rubrics for broad applicability and stratifies them based on the model's competence. By dynamically adjusting rubric weights during training, RuCL guides the model from mastering foundational perception to tackling advanced logical reasoning. Extensive experiments on various visual reasoning benchmarks show that RuCL yields a remarkable +7.83% average improvement over the Qwen2.5-VL-7B model, achieving a state-of-the-art accuracy of 60.06%.
Reinforcement Fine-Tuning for History-Aware Dense Retriever in RAG
Feb 03, 2026Retrieval-augmented generation (RAG) enables large language models (LLMs) to produce evidence-based responses, and its performance hinges on the matching between the retriever and LLMs. Retriever optimization has emerged as an efficient alternative to fine-tuning LLMs. However, existing solutions suffer from objective mismatch between retriever optimization and the goal of RAG pipeline. Reinforcement learning (RL) provides a promising solution to address this limitation, yet applying RL to retriever optimization introduces two fundamental challenges: 1) the deterministic retrieval is incompatible with RL formulations, and 2) state aliasing arises from query-only retrieval in multi-hop reasoning. To address these challenges, we replace deterministic retrieval with stochastic sampling and formulate RAG as a Markov decision process, making retriever optimizable by RL. Further, we incorporate retrieval history into the state at each retrieval step to mitigate state aliasing. Extensive experiments across diverse RAG pipelines, datasets, and retriever scales demonstrate consistent improvements of our approach in RAG performance.
Adaptive Dual-Weighting Framework for Federated Learning via Out-of-Distribution Detection
Feb 01, 2026Federated Learning (FL) enables collaborative model training across large-scale distributed service nodes while preserving data privacy, making it a cornerstone of intelligent service systems in edge-cloud environments. However, in real-world service-oriented deployments, data generated by heterogeneous users, devices, and application scenarios are inherently non-IID. This severe data heterogeneity critically undermines the convergence stability, generalization ability, and ultimately the quality of service delivered by the global model. To address this challenge, we propose FLood, a novel FL framework inspired by out-of-distribution (OOD) detection. FLood dynamically counteracts the adverse effects of heterogeneity through a dual-weighting mechanism that jointly governs local training and global aggregation. At the client level, it adaptively reweights the supervised loss by upweighting pseudo-OOD samples, thereby encouraging more robust learning from distributionally misaligned or challenging data. At the server level, it refines model aggregation by weighting client contributions according to their OOD confidence scores, prioritizing updates from clients with higher in-distribution consistency and enhancing the global model's robustness and convergence stability. Extensive experiments across multiple benchmarks under diverse non-IID settings demonstrate that FLood consistently outperforms state-of-the-art FL methods in both accuracy and generalization. Furthermore, FLood functions as an orthogonal plug-in module: it seamlessly integrates with existing FL algorithms to boost their performance under heterogeneity without modifying their core optimization logic. These properties make FLood a practical and scalable solution for deploying reliable intelligent services in real-world federated environments.
Can Vision-Language Models Handle Long-Context Code? An Empirical Study on Visual Compression
Jan 31, 2026Large Language Models (LLMs) struggle with long-context code due to window limitations. Existing textual code compression methods mitigate this via selective filtering but often disrupt dependency closure, causing semantic fragmentation. To address this, we introduce LongCodeOCR, a visual compression framework that renders code into compressed two-dimensional image sequences for Vision-Language Models (VLMs). By preserving a global view, this approach avoids the dependency breakage inherent in filtering. We systematically evaluate LongCodeOCR against the state-of-the-art LongCodeZip across four benchmarks spanning code summarization, code question answering, and code completion. Our results demonstrate that visual code compression serves as a viable alternative for tasks requiring global understanding. At comparable compression ratios ($\sim$1.7$\times$), LongCodeOCR improves CompScore on Long Module Summarization by 36.85 points over LongCodeZip. At a 1M-token context length with Glyph (a specialized 9B VLM), LongCodeOCR maintains higher accuracy than LongCodeZip while operating at about 4$\times$ higher compression. Moreover, compared with LongCodeZip, LongCodeOCR drastically reduces compression-stage overhead (reducing latency from $\sim$4.3 hours to $\sim$1 minute at 1M tokens). Finally, our results characterize a fundamental coverage--fidelity trade-off: visual code compression retains broader context coverage to support global dependencies, yet faces fidelity bottlenecks on exactness-critical tasks; by contrast, textual code compression preserves symbol-level precision while sacrificing structural coverage.
Group Representational Position Encoding
Dec 08, 2025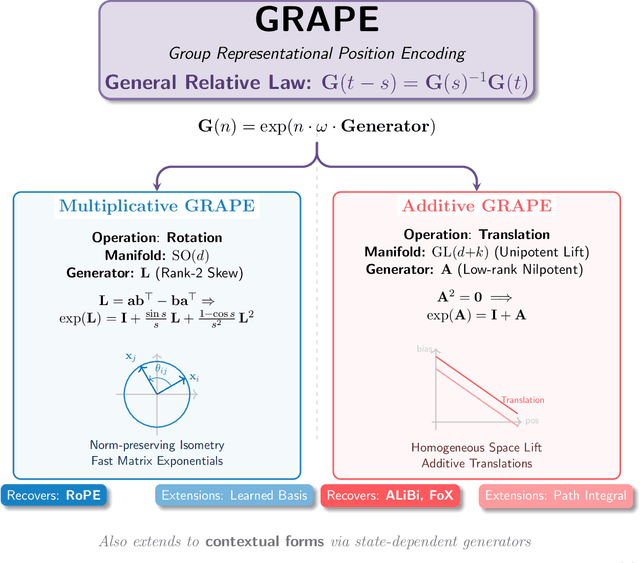
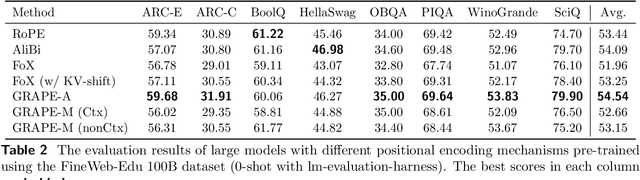
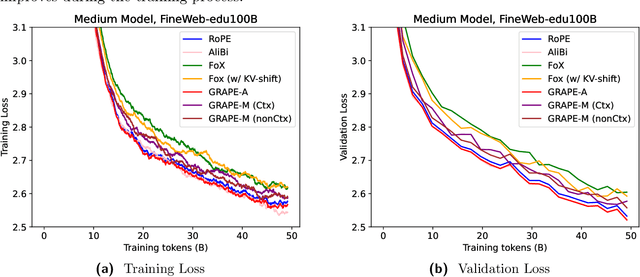

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
Higher-order Linear Attention
Oct 31, 2025The quadratic cost of scaled dot-product attention is a central obstacle to scaling autoregressive language models to long contexts. Linear-time attention and State Space Models (SSMs) provide scalable alternatives but are typically restricted to first-order or kernel-based approximations, which can limit expressivity. We introduce Higher-order Linear Attention (HLA), a causal, streaming mechanism that realizes higher interactions via compact prefix sufficient statistics. In the second-order case, HLA maintains a constant-size state and computes per-token outputs in linear time without materializing any $n \times n$ matrices. We give closed-form streaming identities, a strictly causal masked variant using two additional summaries, and a chunk-parallel training scheme based on associative scans that reproduces the activations of a serial recurrence exactly. We further outline extensions to third and higher orders. Collectively, these results position HLA as a principled, scalable building block that combines attention-like, data-dependent mixing with the efficiency of modern recurrent architectures. Project Page: https://github.com/yifanzhang-pro/HLA.